Kubernetes — deployments, health & traffic
Core details
Pod = smallest schedulable unit (often one main container). Deployment = desired replica count + rolling update strategy.
Service = stable ClusterIP / DNS name load-balancing to ready pods.
Ingress (or Gateway API) = HTTP routing, TLS termination at edge.
Probes
| Probe | Purpose |
|---|---|
| Liveness | restart if stuck (deadlock)—avoid too aggressive |
| Readiness | remove from Service endpoints while starting / draining |
| Startup (optional) | slow JVM/Node warm—don’t kill during boot |
Resource requests/limits: CPU/memory — omit limits carelessly → noisy neighbor; wrong requests → scheduling surprises.
Problem this solves: keep a declared number of healthy workloads serving traffic while nodes, deploys, and individual pods change underneath the service.
Understanding
Rolling update: max unavailable / max surge trade availability vs speed. readiness must fail before SIGTERM on scale-down so in-flight drains.
The visual model below is the boundary to keep in mind: the Deployment controller can create or remove pods at any time, but the Service should only route traffic to endpoints whose readiness probe says they are serving.
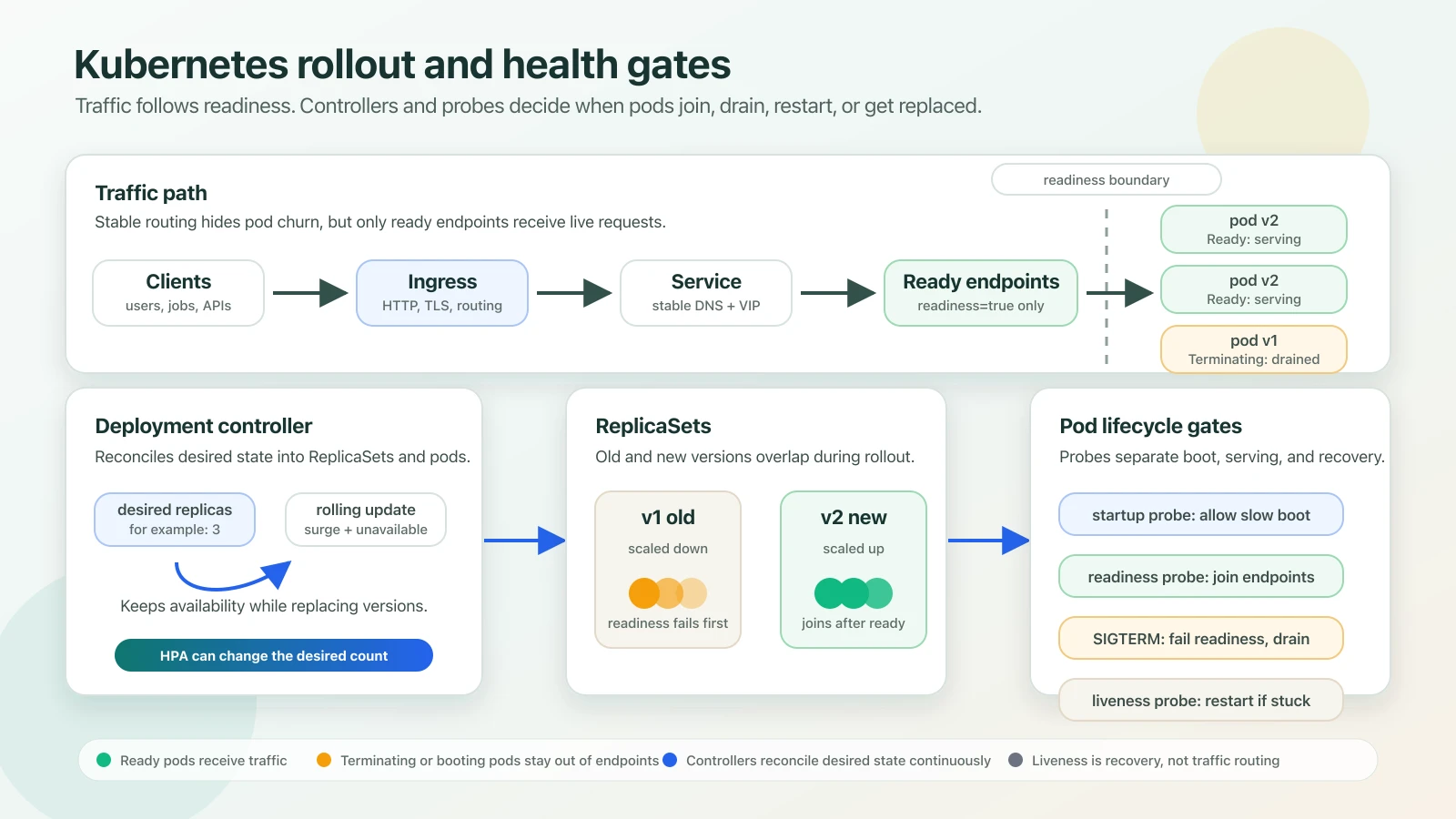
Traffic and shutdown workflow
- New ReplicaSet creates pods for the new image.
- Startup probe protects slow boot from premature liveness restarts.
- Readiness passes only after the app can serve real requests.
- Service endpoints include only ready pods.
- On scale-down or rollout, SIGTERM starts graceful drain.
- Readiness should fail quickly so load balancers stop sending new work.
terminationGracePeriodSecondsmust exceed app drain plus keep-alive behavior.
This is why "the pod is running" is not the same as "the pod should get traffic."
Senior understanding
Link HPA (metrics: CPU, custom, external queue depth). NetworkPolicy for segmentation. Secrets via CSI / external vault—not plaintext in YAML in git.
| Probe | Strong answer |
|---|---|
| "Why not check DB in liveness?" | A DB outage should not restart every healthy pod and amplify recovery |
| "HPA on CPU enough?" | Good for CPU-bound work; queues need lag/depth or request concurrency metrics |
| "What causes CrashLoopBackOff?" | bad config, missing secret, failing startup, process exit, liveness too strict |
| "How avoid dropped requests?" | readiness drain, SIGTERM handler, grace period, load balancer deregistration delay |
Failure modes
- Liveness probe hits
/healththat depends on Redis, causing restart storms during Redis incidents. - Readiness returns success before migrations/config/cache warmup are complete.
- CPU request too low, so pods schedule densely and throttle under load.
- No PodDisruptionBudget, so maintenance evicts too much capacity at once.
- HPA scales on average CPU while one partition or tenant is hot.
Interview drill
Question: "A Kubernetes rollout caused intermittent 502s for two minutes. What is your triage path?"
Model answer structure:
- Correlate 502s with deploy events, pod restarts, readiness transitions, and ingress/load-balancer logs.
- Check whether new pods were marked ready before the app was actually serving.
- Check shutdown: SIGTERM handler, grace period, keep-alive, and endpoint removal timing.
- Inspect resource throttling, CrashLoopBackOff, image pull time, and dependency startup checks.
- Fix the specific gate, then add a rollout metric guard so future canaries stop automatically.
Follow-ups to expect:
- "How would you set maxSurge and maxUnavailable?"
- "What should liveness and readiness each test?"
- "When would you use EKS instead of ECS?"
See also
Mark this page when you finish learning it.
Last updated on
Spotted something unclear or wrong on this page?