AWS compute patterns — ECS, EKS & Lambda
Core details
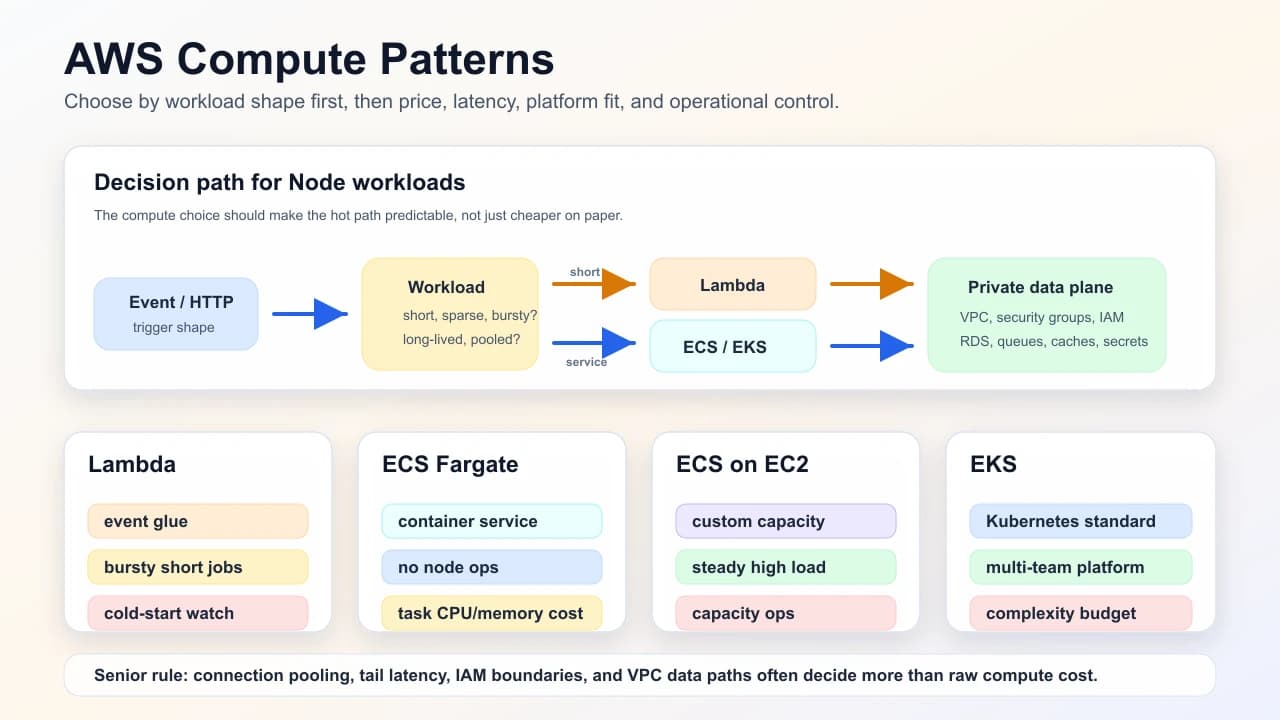
Problem this solves: choose the runtime that fits workload shape, latency, cost, operability, and team maturity instead of defaulting to the service you last used.
| Choice | Sweet spot | Watch |
|---|---|---|
| Lambda | event-driven, bursty, short executions | cold start, 15m cap, VPC ENI latency (mitigations evolve) |
| ECS Fargate | containers without managing nodes | task CPU/mem pricing, platform versions |
| ECS EC2 | need custom AMIs, GPUs, cost at steady high load | ops of capacity |
| EKS | Kubernetes standard, multi-team platform | control plane cost, complexity |
RDS / data in private subnets; tasks in VPC need security groups, NAT for outbound depending on design.
ALB → target group → ECS service / EKS Ingress — health checks align with app readiness.
Understanding
Lambda for transform + orchestration glue; long-lived HTTP APIs often ECS/EKS for connection pooling and predictable latency—interviews reward honest boundaries.
Decision lens
| Workload signal | First choice to consider | Why |
|---|---|---|
| Spiky event handler, seconds long | Lambda | pay per use, simple scaling |
| Long-lived HTTP API with pools | ECS Fargate | container runtime, simpler ops than Kubernetes |
| Multi-team platform already on Kubernetes | EKS | shared Kubernetes abstractions and ecosystem |
| High steady utilization and custom hosts | ECS EC2 or EKS managed nodes | better cost control, more node control |
| Queue worker with predictable concurrency | ECS/Fargate or Lambda | choose by run duration, cold-start tolerance, and dependency pooling |
Tie the choice to the bottleneck. Lambda can be excellent for bursty glue but awkward for connection-heavy workloads. Kubernetes can be powerful for platform teams but excessive for one service with simple scaling.
Senior understanding
Provisioned concurrency / always-on tasks trade money for tail latency. IAM least privilege per task role. Secrets from Secrets Manager / SSM — not env in CI logs.
| Probe | Strong answer |
|---|---|
| "Lambda cold starts?" | quantify p95/p99 impact; use provisioned concurrency only for paths that need it |
| "ECS or EKS?" | ECS for simpler container ops; EKS when Kubernetes platform value outweighs complexity |
| "Private RDS access?" | VPC subnets, security groups, DNS, pool sizing, NAT/endpoints for outbound dependencies |
| "Cost control?" | right-size tasks, autoscaling policy, scheduled capacity, spot where safe, reserved baseline |
Failure modes
- Choosing Lambda for a connection-heavy API and exhausting DB connections during bursts.
- Putting tasks in private subnets without a NAT gateway or VPC endpoints for required outbound calls.
- Reusing broad IAM roles across services, turning one service compromise into account-wide access.
- Scaling workers faster than the downstream database, queue, or third-party API can absorb.
- Treating EKS as "managed everything" while still owning upgrades, ingress, policy, and cluster add-ons.
Interview drill
Question: "You need to run a Node.js API, a thumbnail worker, and a nightly reconciliation job. What AWS compute choices do you make?"
Model answer structure:
- Node API: ECS Fargate behind ALB if the team does not need Kubernetes; EKS only if the platform already exists.
- Thumbnail worker: Lambda for small bounded images; ECS worker if processing can exceed Lambda limits or needs native tooling.
- Nightly job: scheduled ECS task or EventBridge-triggered Lambda depending on duration and dependencies.
- Shared controls: task/function IAM roles, secrets manager, VPC routing, logs/metrics/traces, autoscaling guardrails.
- Cost and reliability: scale by queue depth, cap concurrency to protect dependencies, and measure tail latency/cold starts.
Follow-ups to expect:
- "How do you avoid DB connection storms?"
- "What if the worker needs GPUs?"
- "How do you deploy safely across regions?"
See also
Mark this page when you finish learning it.
Last updated on
Spotted something unclear or wrong on this page?