CI/CD pipelines & quality gates
Core details
CI (continuous integration) merges small changes often; each merge runs automated build + tests. CD is continuous delivery (always releasable) vs continuous deployment (auto to prod)—interviews want you to name which you mean.
Problem this solves: reduce the chance that a bad change reaches users, while keeping feedback fast enough that engineers still trust and use the pipeline.
Pipeline stages (typical)
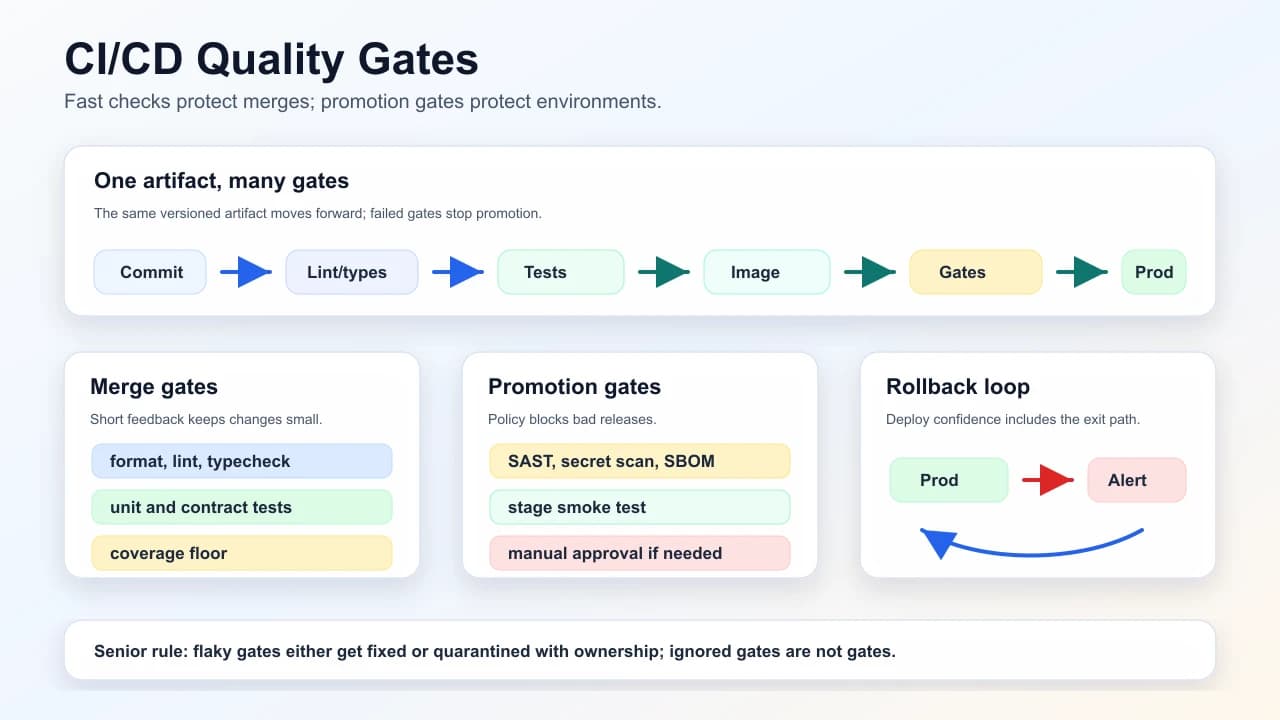
commit → lint/types → unit tests → build image → integration/e2e (optional) →
security scan → push artifact → promote to env (dev/stage/prod)Quality gates: block merge or promotion on coverage floor, SAST findings severity, secret scan, SBOM policy, failed contract tests.
Idempotent deploys: same artifact version → same bits in prod; config via env/parameter store, not hand-edited servers.
Understanding
Fast feedback early (lint/unit in minutes); expensive tests batched or nightly if needed—but release path must have a clear green definition. Flaky tests erode trust; seniors quarantine or fix root cause.
The visual model below separates merge gates from promotion gates: fast checks protect the branch, policy checks protect each environment, and rollback uses the previous known artifact rather than an emergency rebuild.
Gate placement
| Gate | Runs where | Why |
|---|---|---|
| Lint/types/unit | pull request | catches cheap deterministic problems quickly |
| Integration/contract | merge or pre-promote | proves service boundaries and schema compatibility |
| Image scan/SBOM | artifact build | ties security evidence to exact deployable bits |
| Migration check | pre-promote | confirms expand-contract and rollback posture |
| Canary metric gate | production rollout | proves the artifact behaves under real traffic |
Do not put every slow check on every commit if it makes engineers bypass the process. The senior move is separating fast confidence from release confidence while keeping the production path explicit.
Senior understanding
| Probe | Strong angle |
|---|---|
| “Monolith vs multi-service CI” | matrix builds, changed-path optimization, cache layers |
| “Who approves prod?” | environment protection, manual approval vs policy-as-code |
| “Rollback?” | previous artifact + DB migration strategy (expand–contract) |
| “Flaky tests?” | quarantine with owner + expiry; do not silently ignore release gates |
| “Secrets?” | scan commits and build logs; inject runtime secrets outside the artifact |
Failure modes
- Rebuilding the artifact per environment, so staging did not test production bits.
- Allowing manual hotfixes on servers, so Git no longer describes production.
- Letting a flaky test become "known bad" without owner or deadline.
- Running destructive migrations before new code proves compatibility.
- Deploying all regions at once without a canary or traffic-shift lever.
Interview drill
Question: "Design a deployment pipeline for a Node.js API that handles payments."
Model answer structure:
- PR gate: lint, typecheck, unit tests, focused integration tests, secret scan.
- Build: create one image with version, digest, SBOM, and vulnerability policy.
- Pre-prod: run contract tests against payment provider mocks/sandbox and migration compatibility checks.
- Promotion: use the same artifact, runtime config, manual approval if required by risk.
- Production: canary by traffic or tenant, watch payment success rate, latency, error rate, and rollback using previous artifact plus compatible schema.
Follow-ups to expect:
- "Which checks block merge versus deploy?"
- "What if the vulnerability scanner finds a high severity CVE in the base image?"
- "How do you avoid duplicate payment side effects in integration tests?"
Diagram
See also
Mark this page when you finish learning it.
Last updated on
Spotted something unclear or wrong on this page?