Structured outputs, tool calling & guardrails
LLM applications fail when free-form text is treated like a trusted API response. Use structured outputs when the model must return data, tool calling when it needs external data/actions, and guardrails when runtime policy must block or redirect unsafe behavior.
The visual model below separates the model’s proposal from the application’s enforcement layer: schema validation, policy, authorization, idempotency, execution, and observation handling all happen outside the model.
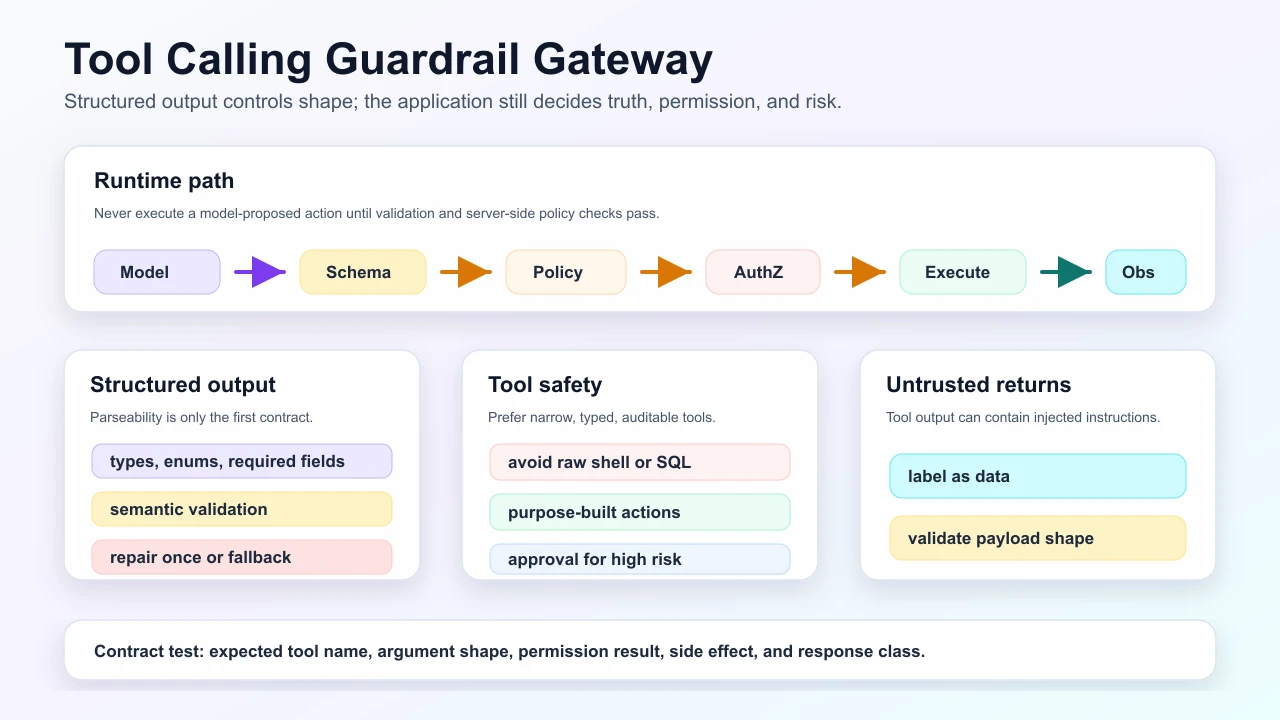
Structured output lifecycle
Key distinction: schema validation checks shape. Semantic validation checks truth and safety.
JSON mode vs structured output vs tool calling
| Mechanism | Best for | Limitation |
|---|---|---|
| JSON mode | "Return parseable JSON." | Does not guarantee your schema. |
| Structured output | Extracting or generating typed data. | Valid values can still be factually wrong. |
| Tool calling | Fetching external data or taking actions. | Tool must be validated, authorized, rate-limited, and audited. |
| Guardrail | Blocking risky inputs, outputs, or tool calls. | Must be part of layered controls, not the only defense. |
Tool calling architecture
The safest tools are small, typed, boring, and auditable.
Tool design examples
| Unsafe tool | Safer tool |
|---|---|
run_sql(query) | get_customer_orders(customer_id, limit) |
send_email(to, subject, body) with no approval | draft_email(ticket_id, recipient_id) then human approval to send |
delete_file(path) | request_file_deletion(file_id, reason) with policy review |
browse_web(url) unrestricted | fetch_allowed_domain_article(article_id) |
shell(cmd) | Purpose-built build/test/deploy actions with allowlists |
Guardrail positions
| Guardrail | Catches |
|---|---|
| Input | Abuse, prompt injection, unsupported intent, PII oversharing. |
| Output | Sensitive leakage, unsupported claims, policy violations, malformed response. |
| Tool input | Overbroad args, unauthorized ids, dangerous side effects. |
| Tool output | Secret leakage, injected instructions, unexpected payload shape. |
Repair loops
Use repair loops carefully:
- Cap repairs, usually one attempt.
- Log the original invalid output and repair reason.
- Do not repair policy violations into allowed actions.
- Prefer deterministic validation errors over vague "try again."
- Fall back to clarification, refusal, or human review after exhaustion.
Interview questions
1. Why is structured output not enough for safety?
- It controls shape, not intent, authorization, or factual correctness.
Follow-up: What else is required?
- Semantic validation, policy checks, user-scoped authorization, idempotency, and evals for bad but valid-looking outputs.
2. What happens after the model emits a tool call?
- The app validates schema, checks policy and permissions, executes the tool if allowed, appends the observation, and asks the model to continue or answer.
3. Where do you put human approval?
- Before irreversible, external, financial, legal, security-sensitive, or destructive tool execution.
4. How do you prevent tool output injection?
- Treat tool output as data, strip/label instruction-like text, validate payload shape, and keep system policy outside retrieved/tool content.
5. What is a good contract test?
- Given an input, assert the expected tool name, argument shape, permission behavior, refusal path, and final response class.
Interview answer template
For "How do you safely connect an LLM to tools?", answer:
- Expose narrow typed tools, not broad SQL/shell/browser access.
- Give the model schemas and descriptions, but execute server-side only after validation.
- Enforce user/tenant authorization in the tool gateway.
- Add idempotency for writes and human approval for high-risk actions.
- Treat tool output as untrusted data when it returns to the model.
- Test expected tool route, args, refusal behavior, and side effects.
Strong phrase:
"Structured output makes the response parseable; the application still decides whether it is true, allowed, and safe."
Common bad answers
| Bad answer | Why it is weak |
|---|---|
| "Use JSON mode and trust the result." | Valid JSON can still be factually wrong or unauthorized. |
| "Let the model generate SQL/API calls." | Broad raw commands bypass narrow tool contracts and server-side policy. |
| "Retry until the JSON parses." | Infinite repair loops burn cost and can hide policy violations. |
Self-check
You are ready if you can explain:
- JSON mode vs structured output vs tool calling.
- Why semantic validation is required after schema validation.
- Where human approval belongs.
- How to design a narrow tool.
- What a contract test should assert.
Related
LLM contracts, context & tools · Agentic production · Safety & injection
Mark this page when you finish learning it.
Spotted something unclear or wrong on this page?