Cost, latency & routing
GenAI cost and latency come from more than the final model call: classification, retrieval, embeddings, reranking, tool IO, retries, context size, observability, and agent loops all matter. Senior designs set budgets before picking models.
Use this rule in interviews:
Optimize for cost per successful outcome, not cheapest model call.
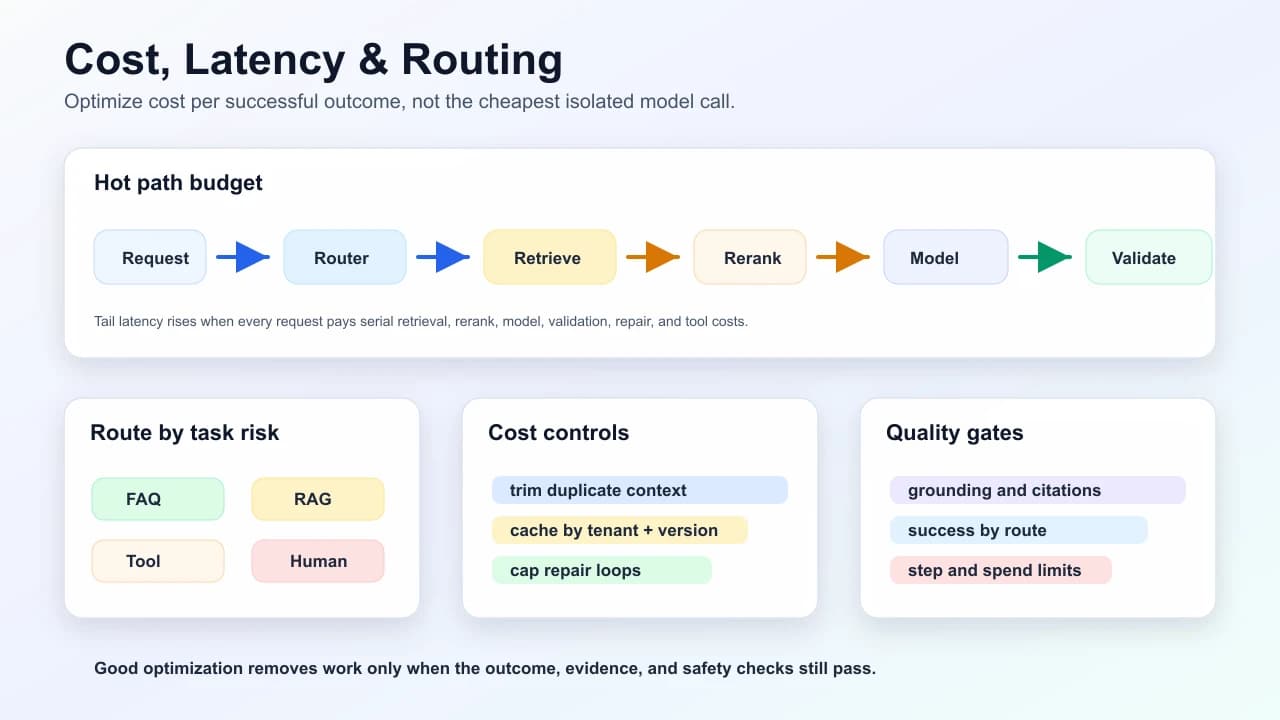
Latency path
Tail latency often comes from serial dependencies: retrieve, then rerank, then model, then repair, then tool. Reduce wall time by parallelizing independent work and removing unnecessary hops from the hot path.
Cost model
Think in components:
total cost =
request classification
+ retrieval/search infra
+ embedding/rerank calls
+ input tokens
+ output tokens
+ tool/API costs
+ retries/repair loops
+ tracing/eval storageFor agents, multiply by steps. A cheap model that loops 12 times can cost more than a stronger model that finishes in 2 steps.
Cost levers
| Lever | Helps | Risk | Guardrail |
|---|---|---|---|
| Smaller model router | Sends easy tasks to cheaper paths. | Misroutes hard tasks. | Measure task success by route. |
| Context trimming | Reduces input tokens and latency. | Drops required evidence. | Track citation support and retrieval recall. |
| Embedding cache | Avoids repeated embedding calls. | Stale or cross-tenant keys. | Include tenant, corpus version, model version. |
| Answer cache | Fast for repeated public FAQs. | Personalized leakage or stale answers. | Use only for public or strict identity-scoped responses. |
| Parallel retrieval | Reduces wall time. | More infra spend. | Parallelize only independent shards. |
| Streaming | Improves perceived latency. | Does not reduce compute. | Use when partial text is safe to show. |
| Step budget | Prevents runaway agents. | Cuts off valid long tasks. | Escalate with partial state and reason. |
| Capped repair loop | Prevents infinite JSON fixing. | May refuse recoverable outputs. | One repair, then deterministic fallback. |
Routing states
Good routers are conservative. When risk or ambiguity is high, route to evidence, tools, or human review rather than guessing cheaply.
Example scenario
Prompt: "A support assistant has p95 latency of 4.2s and cost per resolved ticket doubled after adding RAG."
Strong debugging order:
- Split latency by stage: classify, vector search, keyword search, rerank, model, validation, tool calls.
- Check whether rerank is on every request or only ambiguous/high-value requests.
- Inspect average packed tokens and duplicate chunks.
- Compare answer quality with and without long context.
- Route simple public FAQs away from RAG.
- Cache retrieval results by tenant, query fingerprint, corpus version, and permissions.
- Add step budgets and repair caps if agents are involved.
Bad answer: "Use a faster model." That may help, but it ignores retrieval, context bloat, reranking, serial IO, and routing.
Interview answer template
For "How would you optimize GenAI cost and latency?", answer:
- Define success metric: cost per successful task, p95/p99 latency, quality threshold.
- Break down the path: classify, retrieve, rerank, model, validate, tools, retries.
- Remove unnecessary work: route easy tasks, trim context, skip rerank when recall is clear.
- Parallelize independent work: retrieval shards, metadata lookups, safe prefetch.
- Cache safely: tenant-scoped, corpus-versioned, permission-aware keys.
- Protect quality: evaluate answer quality and grounding after every optimization.
- Add budgets: token, step, retry, wall-clock, and spend limits.
Interview questions
1. How do you lower GenAI cost without hurting quality?
- Route easy tasks to cheaper paths, trim duplicate context, cache safely, cap repair loops, and measure quality deltas on golden tasks before release.
Follow-up: What metric prevents fake savings?
- Cost per successful outcome. Cheaper calls are not savings if task success or human escalation gets worse.
2. What causes tail latency in RAG?
- Slow vector/keyword search, reranker calls, serial IO, large context, provider latency, retries, and validation/repair loops.
Follow-up: What would you remove first?
- Anything on the hot path that does not change answer quality for the current route, often unconditional reranking or oversized packed context.
3. Why is answer caching risky?
- Personalized or tenant-specific responses can leak across users unless keys include identity, permissions, source version, and freshness.
Follow-up: When is answer caching acceptable?
- Public, deterministic FAQ-style answers with clear invalidation. For private data, prefer caching retrieval or embeddings with tenant-aware keys.
4. Why can a smaller model increase total cost?
- It may need more retries, larger prompts, more tool calls, or more human escalation. Measure the whole workflow.
Common bad answers
| Bad answer | Why it is weak |
|---|---|
| "Use a cheaper model." | Ignores retries, quality loss, escalation, and total workflow cost. |
| "Cache every answer." | Can leak personalized data or serve stale/private responses. |
| "Always rerank for quality." | Reranking adds latency and cost; use it where it changes outcomes. |
Self-check
You are ready if you can explain:
- Cost per model call vs cost per successful outcome.
- Why p95 latency is often outside the model call.
- When answer caching is safe.
- How routing reduces cost without hurting quality.
- What budget limits an agent needs.
Related
Mark this page when you finish learning it.
Spotted something unclear or wrong on this page?