Message Queue vs Stream
What it is
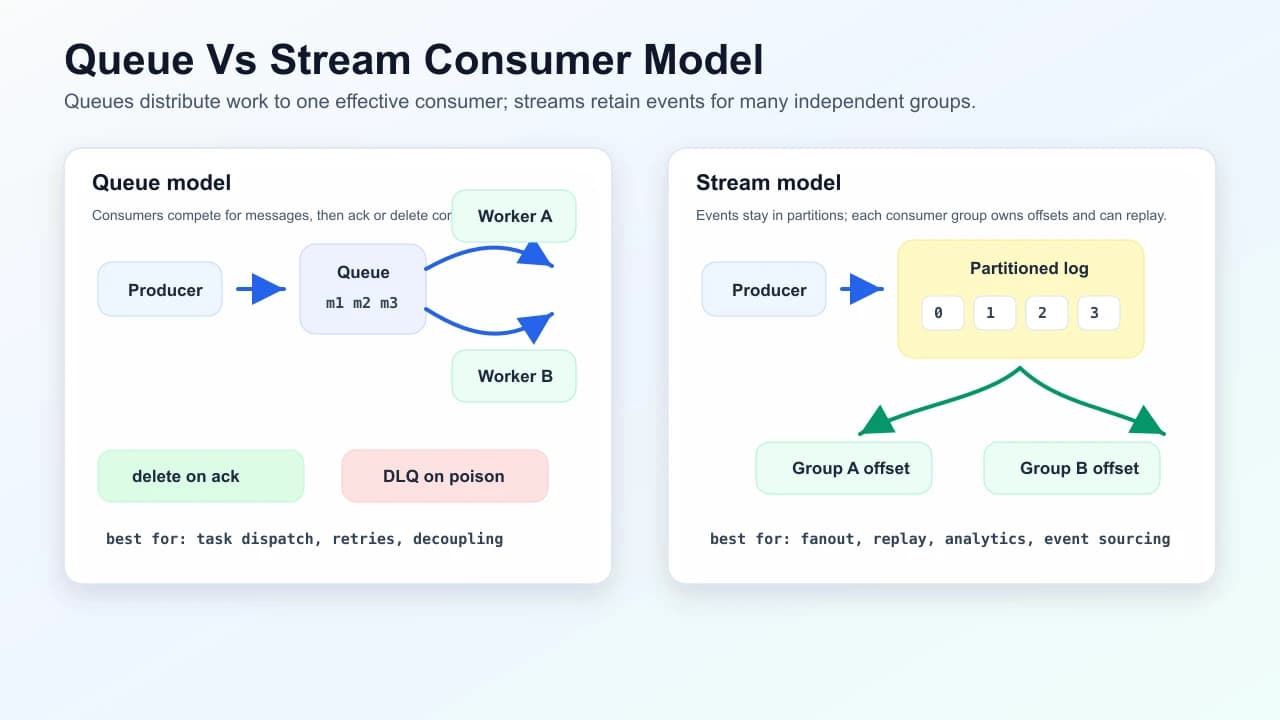
- Message queue (mental model: SQS, RabbitMQ classic queues): producers send messages; consumers pull or receive push; messages are often deleted after successful processing. Good for job dispatch and decoupling services with at-least-once delivery.
- Event stream / log (mental model: Kafka, Pulsar, Kinesis): messages are append-only partitions; consumers track offsets and can replay history. Good for analytics, event sourcing, and multiple independent consumer groups.
When to use
| Need | Favor |
|---|---|
| Simple task queue, per-message visibility timeout | Queue (SQS-like) |
| Fan-out to many services, replay, stream processing | Kafka-like stream |
| Strict ordering for one entity | Single partition key / single shard |
| Global ordering | Hard—usually avoid; partition by key |
Concrete examples
- Queue: image resize jobs after upload. Each image needs one worker, retries are useful, and the message can disappear after successful processing.
- Stream: order lifecycle events. Billing, fulfillment, analytics, and search indexing all consume the same retained history at their own pace.
Processing workflow
- Producer writes business state, ideally using a database outbox when the event must match the transaction.
- Broker stores the message or event and exposes retry, retention, or offset mechanics.
- Consumer processes idempotently using a message id, business key, or dedupe table.
- Consumer acknowledges, deletes, or commits offset only after the side effect is durable.
- Poison messages move to a DLQ with enough metadata to replay or inspect later.
Ordering guarantees
- Single partition / single queue with one consumer: FIFO processing (often exactly one effective consumer at a time).
- Multiple consumers: ordering not global unless you assign partition key so related events share one partition (Kafka) or use FIFO queues with limited throughput (AWS FIFO).
- Queues: ordering between unrelated messages is weak; visibility timeout can cause redelivery and reordering perception.
Loading diagram…
Alternatives
- Synchronous RPC for critical path when you need immediate consistency (simpler operationally, tighter coupling).
- Database outbox pattern: transactional writes + relay to broker—stronger than “fire and forget”.
Failure modes
- Poison messages: infinite retries; use DLQ (dead-letter queue) and alerts.
- Consumer lag: scale consumers; partition bottleneck for streams.
- Duplicate processing: design idempotent handlers (at-least-once is default for many systems).
- Back-pressure: unbounded queues hide overload until catastrophic lag—monitor depth.
Common mistakes
- Assuming "exactly once" means no duplicates anywhere; most designs still need idempotent side effects.
- Committing offsets before the database write succeeds; crashes then lose work.
- Using one partition for perfect order, then discovering throughput is capped by that partition.
- Letting queues grow without an overload policy; lag becomes user-visible long before the broker fails.
Interview talking points
- Clarify delivery semantics: at-most-once vs at-least-once vs exactly-once (often “exactly-once” is effectively via idempotency + offsets).
- Compare ordering scope vs throughput (more partitions → more parallelism, weaker global order).
- Mention replay for streams vs delete-on-ack for queues.
- Relate consumer throughput and end-to-end latency to latency and throughput.
Interview answer shape
- Name the workload: job dispatch, fan-out, replay, ordering, retention, and expected throughput.
- Choose queue or stream and state the reason in one sentence.
- Define delivery semantics and idempotency before discussing scale.
- Pick the ordering key and explain what ordering you are giving up.
- Add operational controls: DLQ, retry backoff, lag alerts, partition count, and replay plan.
Common follow-ups: offset commit timing, visibility timeouts, consumer rebalancing, outbox pattern, and how to recover from a bad deploy that processed messages incorrectly.
Related fundamentals
- Back-of-the-envelope estimation — queue depth, throughput, consumer count
- Latency and throughput
Mark this page when you finish learning it.
Last updated on
Spotted something unclear or wrong on this page?