Bloom Filter
What it is
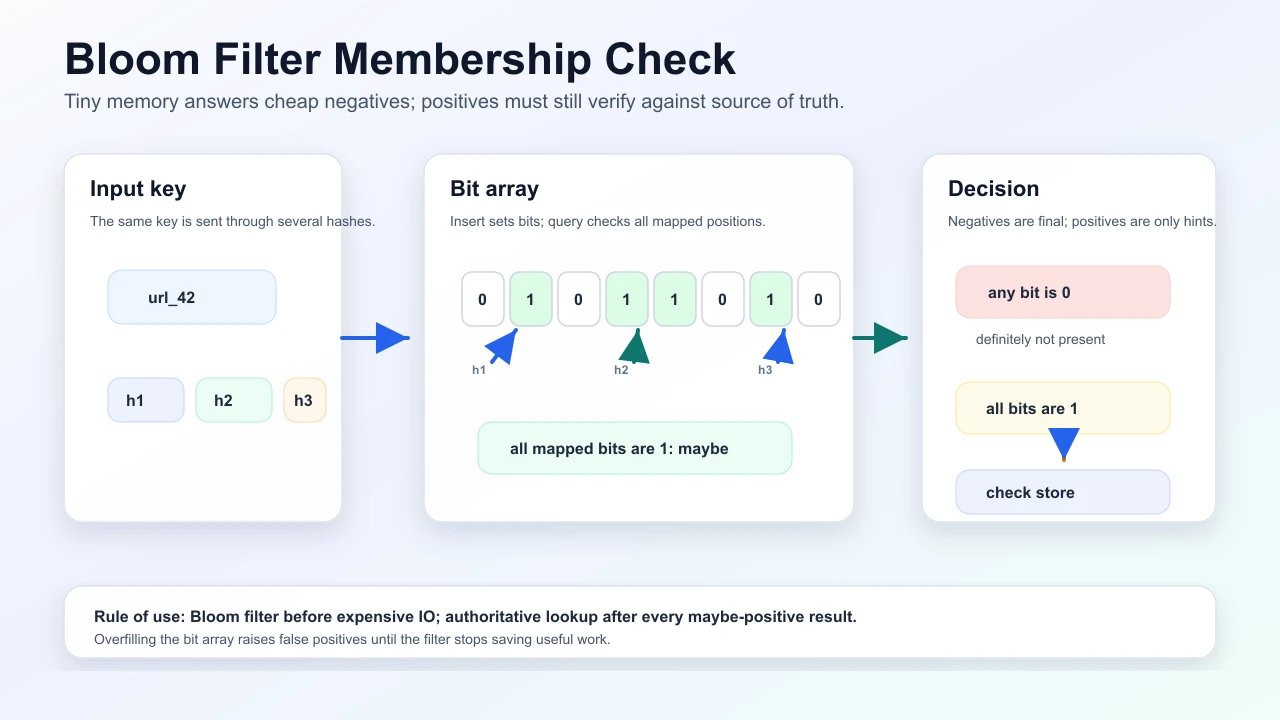
A Bloom filter is a probabilistic set membership structure: a bit array and several hash functions map each element to bit positions. If all those bits are set, the element is maybe in the set; if any bit is clear, the element is definitely not in the set.
How the check works
- On insert, hash the key
kdifferent ways and set those bit positions to1. - On lookup, hash the key the same
kways and inspect the same positions. - If any position is
0, the key was never inserted because insertion would have set every required bit. - If all positions are
1, the key may be present, but those bits could have been set by other keys colliding across the array.
That is the whole one-sided contract: a clear bit proves absence; all set bits only create a candidate that may need verification.
False positive rate
- No false negatives (if implemented correctly for insertions): if the filter says “not present,” it is not.
- False positives are possible: the filter may say “maybe present” when the key was never inserted. False positive rate decreases with a larger bit array and a hash count tuned to the expected element count.
Too few hashes leave information unused; too many hashes set too many bits and make the filter saturate. A common approximation:
n = expected items
m = bits in the filter
k = number of hash functions
falsePositiveRate ~= (1 - e^(-k*n/m))^k
best k ~= (m/n) * ln(2)Example: if n = 10M keys and you can spend about 10 bits per key, m = 100M bits (12.5 MB) and the optimal hash count is about 7. That gives roughly a 0.8% false-positive rate before checking the authoritative store.
If the target false-positive rate is known first, size memory with:
m ~= -(n * ln(p)) / (ln(2)^2)
k ~= (m/n) * ln(2)Example: for 100M keys at 1% false positives, m is about 958M bits (120 MB) and k is about 7. For 0.1%, memory rises to about 180 MB. Lower false positives are not free; they buy fewer extra store lookups with more memory and CPU per query.
Use cases
- Pre-check before expensive lookup: disk/SSD existence, caching layer “maybe in group,” Cassandra and HBase block filters to skip IO.
- Distributed joins: send a compact filter for one side of a join so another service or shard can skip keys that definitely cannot match.
- Crawler “seen URL” checks at huge scale with bounded memory.
- One-sided cheap negative answers to save work.
Concrete example
Suppose a crawler has seen 10B URLs and cannot keep the exact set fully in memory on every worker. A Bloom filter lets each worker identify URLs that are definitely not in the seen set and send them to the authoritative store for insert/enqueue. When the filter says maybe present, the worker checks the authoritative URL store before dropping the URL, because a false positive would otherwise lose crawl coverage.
Classic Bloom filter: no delete
Standard Bloom filters do not support reliable delete without risking false negatives. Counting Bloom filters use counters per slot to allow delete at higher memory cost. Cuckoo filters are an alternative with delete support and good space efficiency in some workloads.
insert(key): for each hash: bit[hash(key, index)] = 1
maybePresent(key): all those bits are 1 -> maybe
any bit 0 -> definitely noWhen to use
- Huge universe of keys; acceptable occasional extra positives; need tiny memory vs exact set.
Alternatives
- Hash set in memory: exact, but memory grows with every key.
- Sketches (Count-Min, HyperLogLog) for different questions (frequency, cardinality).
Data structure comparison
| Structure | Answers | Errors | Use when |
|---|---|---|---|
| Hash set | Exact membership | None if data fits and is available | Correctness needs exact answers and memory is acceptable |
| Bloom filter | Probable membership | False positives, no false negatives for inserts | Cheap negatives save expensive IO or network calls |
| Counting Bloom filter | Probable membership with delete | False positives plus counter overflow risk | Deletes are needed and extra memory is acceptable |
| Cuckoo filter | Probable membership with delete | False positives; insertion can fail near high load | You need delete with compact storage and manageable rebuilds |
| HyperLogLog | Approximate cardinality | Estimation error | You need "how many unique?", not "is this key present?" |
| Count-Min Sketch | Approximate frequency | Overestimates counts | You need "how often did this key appear?", not exact membership |
Simpler example
In an LSM database or cache-heavy service, a Bloom filter can sit before a disk segment or remote store. If the filter says definitely not present, skip the expensive lookup. If it says maybe present, perform the real lookup and accept that some of those lookups will be wasted false positives.
Failure modes
- Overfilled filter (too many keys for bit array size): FP rate becomes useless.
- Assuming no FP in correctness-critical paths without verification step.
- Delete on classic filter breaks correctness.
- Wrong sizing assumption: expected cardinality grows but the filter is not rebuilt or rotated.
- Poor hash independence: correlated hashes raise false positives beyond the estimate.
Common mistakes
- Using a Bloom filter as the source of truth instead of a pre-check.
- Forgetting the rebuild/rotation plan when the key population grows.
- Applying it where false positives change correctness rather than only adding extra work.
- Ignoring serialization/versioning when filters are shipped between services.
Operational signals
- Estimated fill ratio, measured false-positive rate from sampled authoritative checks, lookup QPS saved, and authoritative lookup fallback rate.
- Filter build time, distribution lag, memory footprint, and version mismatch across nodes.
Interview talking points
- Always pair Bloom pre-check with authoritative store lookup on positives.
- Explain hashes and bits; relate FP to array size and hash count; estimate memory with back-of-envelope.
Interview answer shape
- State the problem: exact set membership is too expensive in memory or IO, and false positives are acceptable.
- Explain the one-sided contract:
definitely not presentis final;maybe presentmust be verified if correctness matters. - Size it from expected cardinality, memory budget, and target false-positive rate.
- Discuss lifecycle: rebuild/rotate when overfilled, distribute versions safely, and use counting Bloom or Cuckoo filters if delete is required.
- Connect to system impact: fewer disk/store lookups, lower read amplification, but extra positives still hit the authoritative store.
Common follow-ups: why there are no false negatives, how false positives happen, how to choose m and k, delete support, overfilling, hash quality, and Bloom filter vs hash set vs HyperLogLog.
Follow-up answers
- Why no false negatives? Insert sets every bit that lookup will later check for that key. If one checked bit is
0, no successful insert for that key happened in this filter version. - How false positives happen: different inserted keys can collectively set all positions for a never-inserted key, so lookup sees all
1s even though the exact set does not contain it. - How to choose
mandk: start with expected item countnand acceptable false-positive ratep, compute memorym, then choosek ~= (m/n) * ln(2). Leave headroom or rotate before the filter exceeds planned cardinality. - Why delete is unsafe in classic Bloom filters: clearing a bit for one deleted key may clear a bit needed by another inserted key, creating a false negative.
- When not to use it: do not use a Bloom filter as the final authority for permissions, payments, idempotency, or any path where a false positive changes correctness instead of only adding extra verification work.
Interview questions
- Why can a Bloom filter have false positives but not false negatives for inserted keys?
- Given
nexpected keys and a1%false-positive target, how would you estimate memory and hash count? - Why is a Bloom filter unsafe as the only check before dropping a URL, payment id, or permission record?
Memory hooks
not presentis final;maybe presentneeds verification when correctness matters.- Bigger
mreduces false positives; too many hashes can saturate the filter. - Bloom filters answer membership, not counts or frequencies.
Related fundamentals
- Back-of-the-envelope estimation
- Latency and throughput — fewer authoritative lookups improves read path throughput
Mark this page when you finish learning it.
Last updated on
Spotted something unclear or wrong on this page?